Distance-based Discriminator
Given dataset of datapoints (where ) and corresponding labels (where each ), we can extract some useful patterns among the datapoints and then essentially forget the dataset. This procedure is called learning and the models which learn useful parameters from the dataset are known as parametric models. For simplicity we can assume that there are only 2 classes ( can be considered 1 and can be considered or ).
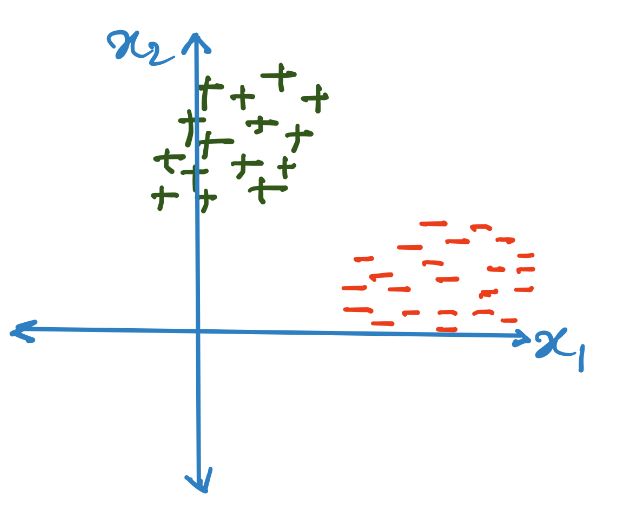
In the dataset described in the above image, we already know the labels. So, we can learn the means of the class conditional datapoints, i.e.
We can create a simple discriminator function by comparing the new datapoint with the class conditional means, with the label of the new datapoint being same as the most similar mean, i.e.
Fisher Discriminant Analysis
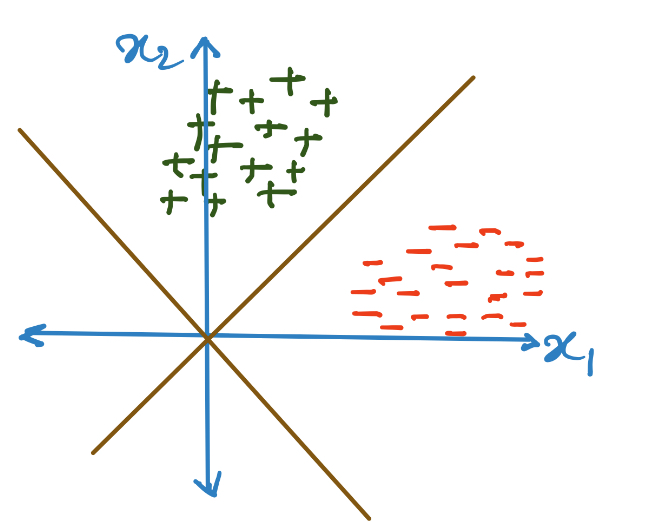
We can additionally assume the dataset to be sampled from a Gaussian. Fisher thought of trying to find a linear projection of the given dataset. This data can be projected on the standard basis or on other subspaces as shown below (linear projections):
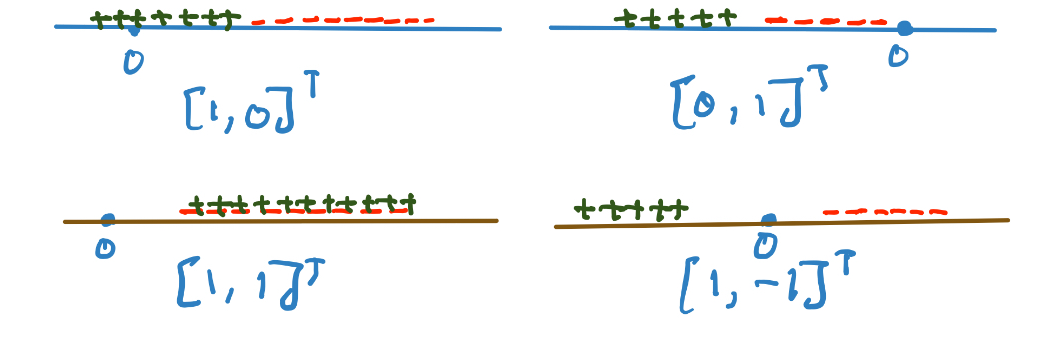
As we can see, not all choices for the linear projection are equally got at preserving the class information and giving a classifier which might generalize well.
We want to identify a vector for linear projection that
- maximizes the between-class spread, and
- minimizes the within-class spread.
Let the means after the linear projection be and , and the variances be and .
So, we would like to make the following ratio big:
We can assume that and where and are the actual means of the class conditional data distributions. Therefore:
Similarly can be written as:
where is the covariance matrix of the entire dataset.
Again,
Therefore, the objective is:
We can take the gradient:
Thus, the projection surface is along the direction .
Probabilistic view of Discriminant Analysis
We can learn a generative model and estimate the distribution that generated the dataset for each class separately, i.e. . Given the generative model, we can use Bayes rule to design an optimal classifier.
Since we are in the binary classification domain ():
We can denote prior probabilities as where and can be estimated from the dataset as:
Therefore:
In the context of Discriminant Analysis, we assume that the class conditional datapoints were sampled from Gaussian distributions. Since we are considering the binary classification problem, the parameters are and for the positive and negative class respectively.
Given a class label, it is easy to estimate the parameters Class conditional sample mean: , and Class conditional sample covariance matrix: Additionally, we already know the priors:
Now all we need to do is find a decision rule. The decision boundary is given by the region where .
Quadratic Discriminant Analysis
For a gaussian:
Classification rule (for QDA): Let the ratio be
Then if else .
Linear Discriminant Analysis
We can further assume that we have the same covariance matrix for both the classes, i.e. .
We can expand
Therefore,
where is a constant.
Notice that the term is just the linear projection of onto the direction , which is similar to Fisher Discriminant Analysis. Actually, LDA is exactly same as FDA, just derived from the probabilistic perspective.
Updated decision rule (for LDA): if else .